The Applied LLM Engineering Blueprint: Memory, RAG, and Agents
Memory systems
LLM Chat bots have 3 common memory systems:
- Context(Short-Term memory) - includes the current conversation history and data injected via prompt
- Fast - no external lookup
- Expensive - consumes context window
- Vector database(Long-Term memory) - Stores Embeddings (for searching) mapped to Raw Text Chunks (for reading).
- Can store huge document amount
- Dynamic - can be changed any time
- Metadata filtering
- Hybrid searching - by vectors and exact query
- Model Weights(Internal memory) - Knowledge "baked in" during training or Fine-Tuning.
- Static - could be changed only with re-train/fine tune
- Hard to Cite: The model "knows" things but can't point to a specific file or URL unless it was in the training text.
Context management
The general goal of context management is efficient prompt building for next processing. We can use the following strategies:
- Caching
- Prompt caching: remove duplicates from the prompt.
- Semantic caching: search for answer in the database to prevent LLM usage entirely.
- Sliding window - Drop oldest messages to free space for new.
- Summarization - Shrink previous N turns into 1-paragraph summary.
- Truncation - Cut data when context window limit exceed.
Primary Architectures
Reasoning Model or Orchestrator is the "general" brain of whole system, it coordinates the workflow and uses utility models to improve performance.
RAG (Retrieval Augmented Generation)
Knowledge database preparing:
- Chunk text with "smart" strategy e.g. use Semantic chunking to prevent half sentence splitting.
- Pick suitable embedding model.
The RAG workflow consist of several steps:
- Retrieve - search query related chunks in the database (e.g. Chroma DB), - we can use vector search or exact , or even both at same time.
- Rank - use reranking model to select only most related chunks.
- Augment - attach found chunks(text representation) to the prompt
- Generate - invoke the LLM with built prompt
Agent: ReAct (Reason Act)
Autonomous LLM agents also not so complex, usually it contains of
- Tools Definition (Contract) - structured schemas (eg
JSON) defining what a tool does and what arguments it requires. - Reasoning Engine - LLM decides which tool to use and why.
- Validation system - must validate that Plan provided by LLM corresponding with available tools.
- Execution environment - Sandbox where tool run.
Common Agent loop:
- Plan - Create chain of actions based on user query
- Execute - Call 1st tool in the chain
- Observe - Captures tool output/error
- Reflect - Is the goal reached ?
- Yes - Return final answer
- No - Append tool feedback to history and go to step
1
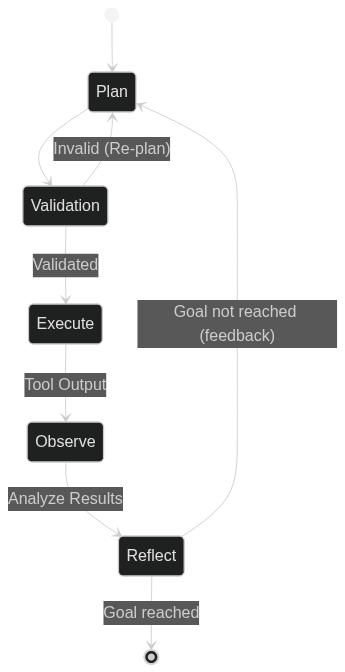
Important highlights: some tasks could be performed in one step like: "create file , write "132" inside it and close it", but what about "download album and play 3rd track from it", it requires at least 3 steps
- download album (download tool only return downloaded path)
listdirto find track inside the album- play 3rd track inside founded folders
Support Infrastructure
Utility LLM models (usually small) models - "backbone brain" of the system. It supports primary model.
- Routing: Direct queries to the most effective model
- Guardians:
- Input: jailbreak detection, prompt injection defense
- Output - PII masking(remove personal information from answer)
- Evaluators (Quality control): Measure performance using "LLM as a Judge" pattern to grade performance on Faithfulness, Relevance , Latency